近日,上海创智学院AI Infra团队发布的 siiRL 2.0,以其卓越特性为强化学习的发展带来了新的突破,沐曦集成电路(上海)股份有限公司(以下简称“沐曦股份”)则凭借自身优势为siiRL 2.0的升级提供了坚实支撑,共同推动强化学习正式迈入“千卡级”时代。
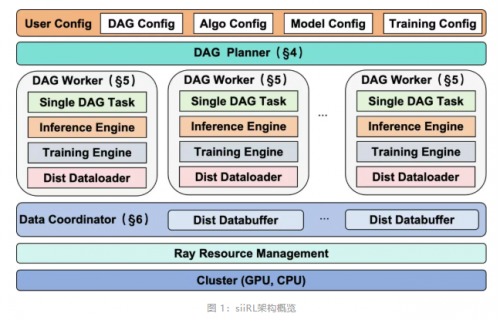
上海创智学院AI Infra团队发布siiRL 2.0,聚焦性能、生态与前沿探索全面升级。一、卓越性能与扩展性:基于全分布式架构,实现千卡级近线性扩展与业界领先吞吐,性能在7B~235B(Dense/MoE)等大规模模型上稳定验证;二、自主可控,拥抱国产算力:全面适配多家主流国产芯片并完成千卡级扩展验证,为AI基础设施夯实自主可控的算力底座;三、灵活易用与生态兼容:独创DAG工作流支持无代码算法实验,兼容Megatron/FSDP等主流后端,极大提升研发效率;面向前沿,四、支持多智能体研究:内建强大的多智能体协同训练框架,为探索“智能涌现”等前沿课题提供关键基础设施。
在本次siiRL的升级适配工作中,沐曦股份做了一系列针对性优化。一、siiRL框架高效适配:基于沐曦股份自研的MXMACA软件栈,已经完整适配了siiRL需要的所有后端引擎(Vllm/Pytorch fsdp/Megatron-LM/Ray)以及深度优化的mccl高性能通信库,不需要其他额外的适配工作,实现了siiRL框架的高效适配;二、超节点scale up:沐曦股份Dragonfly超节点,提供了64卡的光互连高速通信带宽。在训练过程中,通过设置fsdp_size=64,可以充分利用超节点内的带宽,提升模型的训练效率。三、显存优化:通过设置模型参数offload选项,在共置集群上,有效降低了rollout和training阶段的峰值显存,可以采用更优的切分方式,进一步提升计算效率;四、分布式策略调整:结合实际负载与硬件拓扑,优化了不同模型的分布式训练参数切分方式,并调整了亲和性配置,以提升通信效率。
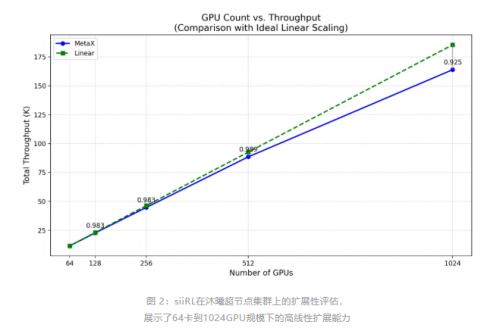
通过上述优化,siiRL框架在沐曦股份超节点集群上实现了从64卡到1024卡的稳定扩展,系统保持了超过92%的高线性度拓展效率。在模型精度上,与国际主流生态 GPU的训练结果相比,沐曦股份超节点集群在验证集上的平均绝对误差控制在0.5%以内,满足实际应用场景的精度要求。
随着AI技术逐渐成为国家科技竞争的核心,构建自主可控的算力基础设施已经成为产业发展的必然选择。沐曦股份与上海创智学院AI Infra团队的携手合作,不仅验证了国产GPU在前沿AI应用上的可行性与先进性,更为中国科研机构、产业界提供了面向未来的坚实算力底座。
未来,沐曦股份将持续与产学研伙伴深度协作,推动大模型框架与国产GPU的深度适配和生态完善,加速强化学习、大模型、智能体等关键领域的创新应用落地。

原标题:强化学习进入“千卡级”时代,沐曦股份助力siiRL 2.0全面升级







 广告
广告




 广告
广告
 广告
广告


