在数字化浪潮奔涌的当下,云环境已成为技术创新与应用拓展的关键阵地。大型语言模型(LLMs)凭借其强大的语言理解与生成能力,在云环境中得到了越来越广泛的应用,从智能客服的高效交互到内容创作的智能辅助,从智能翻译的精准输出到数据分析的智能洞察,LLMs 正深刻改变着各行各业的运营模式与服务体验。然而,随着 LLMs 应用的深度与广度不断拓展,一系列严峻的安全问题也随之浮出水面,尤其是模型机密性和数据隐私方面的隐患,如同一把高悬的达摩克利斯之剑,给行业的健康发展带来了巨大挑战。
现有基于 CPU 的 TEE 实现,在面对 LLMs 推理和训练时却显得力不从心。LLMs 的推理和训练过程涉及海量数据的处理与复杂运算,对计算资源的需求呈指数级增长。传统基于 CPU 的 TEE,由于其计算能力的局限,难以满足如此高强度的资源需求,在处理速度和效率上无法达到理想状态,这在一定程度上限制了 LLMs 在安全环境下的广泛应用与进一步发展。
面对这一困境,微云全息(NASDAQ: HOLO)凭借其敏锐的技术洞察力与勇于探索的创新精神,开展了一项具有开创性的研究工作。首次在支持 TEE 的机密计算环境中对 DeepSeek 模型进行全面评估,特别引入了 Intel Trust Domain Extensions(TDX)技术,为解决问题开辟了新的路径。
在研究过程中,微云全息对 DeepSeek 模型在纯 CPU、CPU - GPU 混合和基于 TEE 的不同实现方式下的性能,展开了严谨且全面的基准测试。测试结果令人振奋:对于较小的参数集,如 DeepSeek - R1 - 1.5B,基于 TDX 的实现在安全环境中执行计算时,性能表现显著优于传统的 CPU 版本。这一发现意义非凡,它充分证明了即使在资源受限的系统中,借助 TDX 技术,依然能够在保障数据安全与模型机密性的同时,高效地部署 LLM 模型,为那些对安全性要求极高且资源有限的应用场景带来了新的希望。
通过进一步深入分析不同模型大小下的性能数据,微云全息发现 GPU 与 CPU 的整体性能比平均达到 12,并且较小的模型呈现出相对较低的比率。这一精准的数据为优化计算资源的配置提供了关键依据,有助于开发者在实际应用中,根据不同模型的特点,更加科学合理地分配 CPU 和 GPU 资源,从而显著提升计算效率,降低计算成本。
此外,微云全息的研究并不仅限于性能测试,还深入到优化 CPU - GPU 机密计算解决方案的层面,为实现可扩展和安全的 AI 部署提供了宝贵的基础见解和指导。这些见解和指导涵盖了从硬件资源的巧妙搭配,到软 件算法的精细优化,再到系统架构的合理设计等多个关键方面,为构建高效、安全且可扩展的 AI 计算环境提供了一套全面且系统的思路。
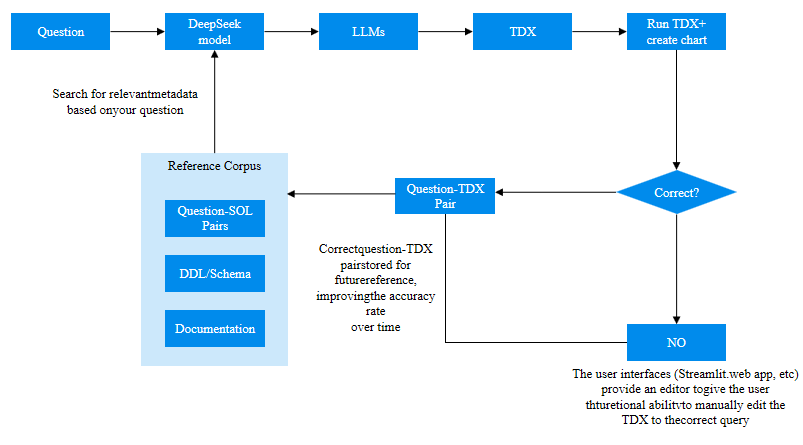
微云全息(NASDAQ: HOLO)通过在机密计算环境中对 DeepSeek 模型的深入研究与实践,为在同样环境下进行高效和安全的 LLMs 推理奠定了坚实基础。未来,有望在更多领域实现安全与效率并重的 AI 部署,助力各行业在严守数据隐私和模型机密的前提下,充分释放 LLMs 的巨大潜力,推动行业向智能化、安全化的方向加速迈进。

原标题:微云全息(NASDAQ: HOLO)解锁 LLMs 安全计算密码:TDX 赋能 DeepSeek 模型高效部署







 广告
广告




 广告
广告

 广告
广告


